Latest Microsoft DP-200, DP-201 Actual Free Exam Questions, 100% free
Here you will find the latest Microsoft DP-200,DP-201 actual exam questions for free. https://www.pass4itsure.com/role-based.html Studying DP–200, DP-201 study guide to help you 100% pass exam.
If you want to get Microsoft certification: Azure Data Engineer Assistant certification, you need to pass the DP-200 and DP-201 exams.
DP-200: Certification Study Guide – pass4itsure.com
- Implement data storage solutions (40-45%)
- Manage and develop data processing (25-30%)
- Monitor and optimize data solutions (30-35%)
updated on March 31, 2020 https://docs.microsoft.com/en-us/learn/certifications/exams/dp-200
latest Microsoft DP-200 actual exam questions
QUESTION 1
You need to develop a pipeline for processing data. The pipeline must meet the following requirements.
-Scale up and down resources for cost reduction.
–
Use an in-memory data processing engine to speed up ETL and machine learning operations.
–
Use streaming capabilities.
-Provide the ability to code in SQL, Python, Scala, and R.
–
Integrate workspace collaboration with Git. What should you use?
A.
HDInsight Spark Cluster
B.
Azure Stream Analytics
C.
HDInsight Hadoop Cluster
D.
Azure SQL Data Warehouse
Correct Answer: B
QUESTION 2
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result, these questions will not
appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior.
You need to implement logging.
Solution: Configure Azure Data Late Storage diagnostics to store logs and metrics in a storage account.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
QUESTION 3
You are a data architect. The data engineering team needs to configure a synchronization of data between an onpremises Microsoft SQL Server database to Azure SQL Database. Ad-hoc and reporting queries are being overutilized
the on-premises production instance. The synchronization process must:
1.
Perform an initial data synchronization to Azure SQL Database with minimal downtime
2.
Perform bi-directional data synchronization after initial synchronization
3.
You need to implement this synchronization solution. Which synchronization method should you use?
A. transactional replication
B. Data Migration Assistant (DMA)
C. backup and restore
D. SQL Server Agent job
E. Azure SQL Data Sync
Correct Answer: E
SQL Data Sync is a service built on Azure SQL Database that lets you synchronize the data you select bi-directionally
across multiple SQL databases and SQL Server instances. With Data Sync, you can keep data synchronized between
your on-premises databases and Azure SQL databases to enable hybrid applications.
Compare Data Sync with Transactional Replication

References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-sync-data
QUESTION 4
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and
authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct
selection is worth one point.
Hot Area:
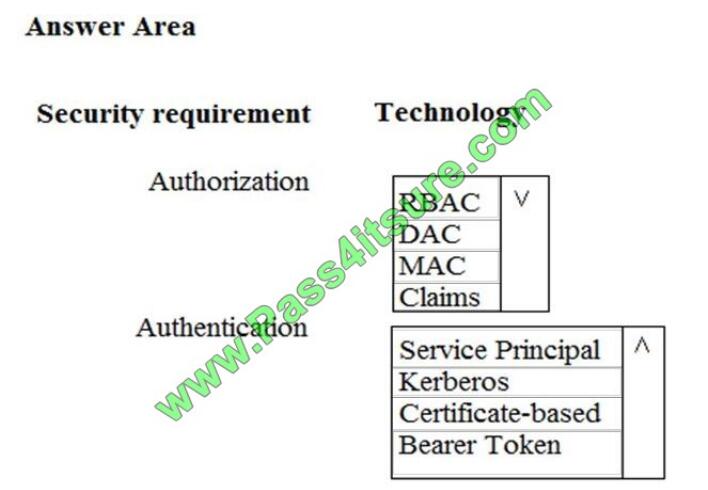
Correct Answer:

Explanation/Reference:
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand
QUESTION 5
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a
unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure HDInsight. Batch
processing will run daily and must:
Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale.
Solution: Monitor cluster load using the Ambari Web UI.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Ambari Web UI does not provide information to suggest how to scale.
Instead monitor clusters by using Azure Log Analytics and HDInsight cluster management solutions.
References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-manage-ambari
QUESTION 6
You need set up the Azure Data Factory JSON definition for Tier 10 data.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Connection String
To use storage account key authentication, you use the ConnectionString property, which xpecify the information
needed to connect to Blobl Storage.
Mark this field as a SecureString to store it securely in Data Factory. You can also put account key in Azure Key Vault
and pull the accountKey configuration out of the connection string.
Box 2: Azure Blob
Tier 10 reporting data must be stored in Azure Blobs

References: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-blob-storage
QUESTION 7
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases
at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid
single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
A. Install a standalone on-premises Azure data gateway at each location
B. Install an on-premises data gateway in personal mode at each location
C. Install an Azure on-premises data gateway at the primary location
D. Install an Azure on-premises data gateway as a cluster at each location
Correct Answer: D
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can
access on-premises data resources used in Power BI reports and dashboards. Such clusters allow gateway
administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power
BI service always uses the primary gateway in the cluster, unless it\\’s not available. In that case, the service switches to
the next gateway in the cluster, and so on.
References:
https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
QUESTION 8
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and
processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place:

Correct Answer:
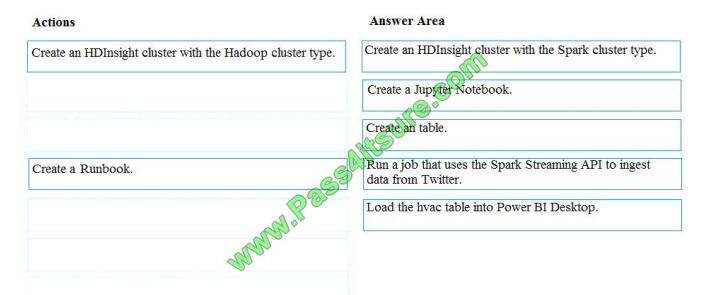
Step 1: Create an HDInisght cluster with the Spark cluster type
Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table.
Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data.
References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
QUESTION 9
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an
Azure SQL Data Warehouse for further transformation. You need to implement the solution. Which four actions should
you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and
arrange them in the correct order.
Select and Place:

Correct Answer

QUESTION 10
You need to ensure phone-based polling data upload reliability requirements are met. How should you configure
monitoring? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one
point.
Hot Area:
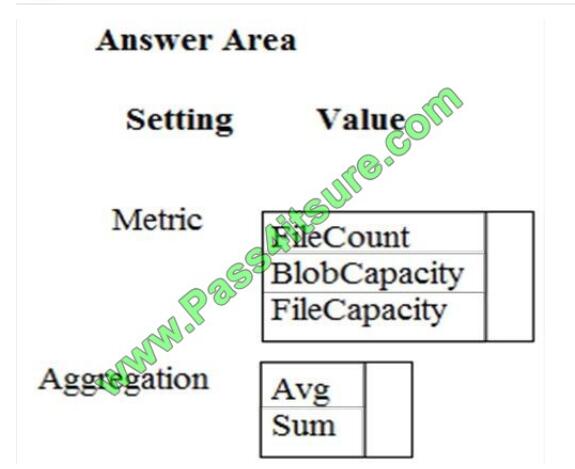
Correct Answer:

Explanation/Reference:
Box 1: FileCapacity
FileCapacity is the amount of storage used by the storage account
QUESTION 11
You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have
the following code:

Which database and authorization types are used? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
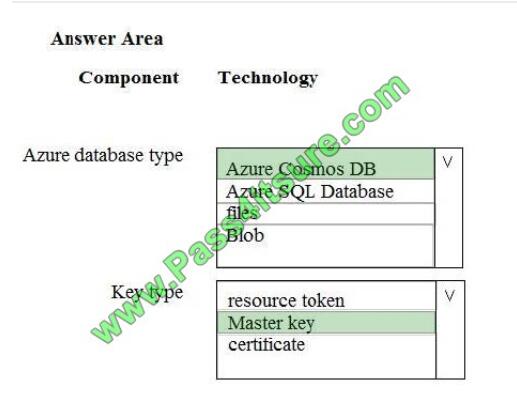
Box 1: Azure Cosmos DB
The DocumentClient.CreateDatabaseAsync(Database, RequestOptions) method creates a database resource as an
asychronous operation in the Azure Cosmos DB service.
Box 2: Master Key
Azure Cosmos DB uses two types of keys to authenticate users and provide access to its data and resources: Master
Key, Resource Tokens
Master keys provide access to the all the administrative resources for the database account. Master keys:
Provide access to accounts, databases, users, and permissions.
Cannot be used to provide granular access to containers and documents.
Are created during the creation of an account.
Can be regenerated at any time.
Incorrect Answers:
Resource Token: Resource tokens provide access to the application resources within a database.
References:
https://docs.microsoft.com/en-us/dotnet/api/microsoft.azure.documents.client.documentclient.createdatabaseasync
https://docs.microsoft.com/en-us/azure/cosmos-db/secure-access-to-data
QUESTION 12
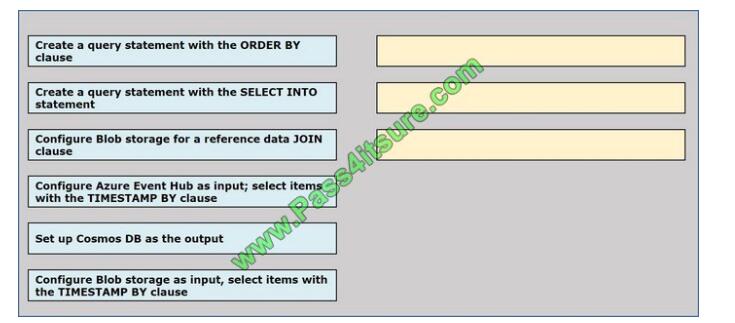
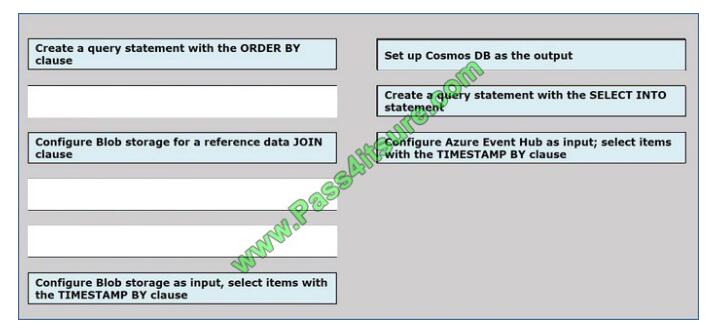
You implement an event processing solution using Microsoft Azure Stream Analytics.
The solution must meet the following requirements:
-Ingest data from Blob storage
-Analyze data in real time
-Store processed data in Azure Cosmos DB
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
QUESTION 13
You manage a Microsoft Azure SQL Data Warehouse Gen 2.
Users report slow performance when they run commonly used queries. Users do not report performance changes for
infrequently used queries
You need to monitor resource utilization to determine the source of the performance issues. Which metric should you
monitor?
A. Cache used percentage
B. Local tempdb percentage
C. WU percentage
D. CPU percentage
Correct Answer: B
Full Microsoft DP-200 dumps https://www.pass4itsure.com/dp-200.html
Microsoft DP-200 Pdf Dumps
[PDF Download] https://drive.google.com/open?id=1MdsDECN7dqml2OMJ0XQ-5LaNMQ__ZwXm
DP-201: Certification Study Guide – pass4itsure.com
- Design Azure data storage solutions (40-45%)
- Design data processing solutions (25-30%)
- Design for data security and compliance (25-30%)
updated on March 26, 2020 https://docs.microsoft.com/en-us/learn/certifications/exams/dp-201
latest Microsoft DP-201 actual exam questions
QUESTION 1
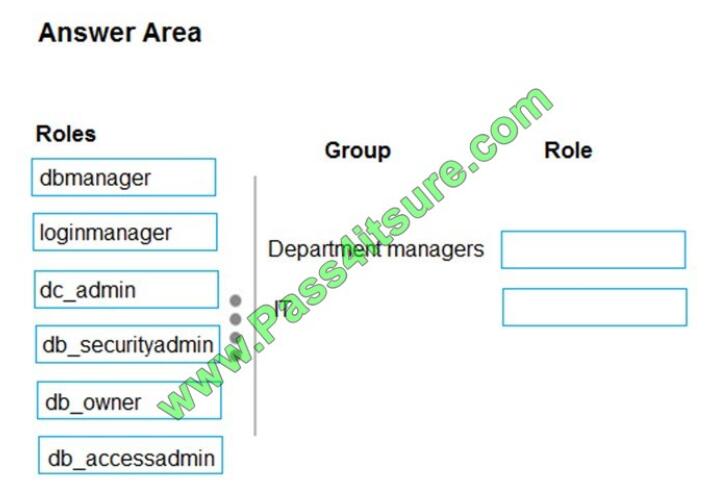
You are designing an Azure SQL Data Warehouse for a financial services company. Azure Active Directory will be used
to authenticate the users.
You need to ensure that the following security requirements are met:
Department managers must be able to create new database.
The IT department must assign users to databases.
Permissions granted must be minimized.
Which role memberships should you recommend? To answer, drag the appropriate roles to the correct groups. Each
role may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to
view
content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
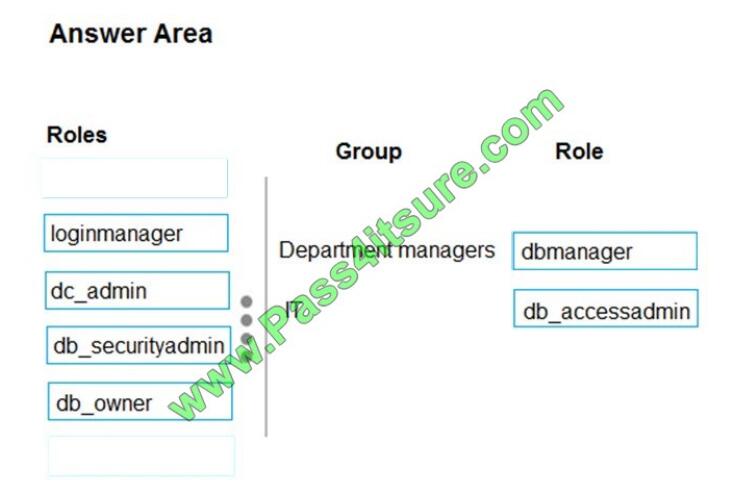
Box 1: dbmanager
Members of the dbmanager role can create new databases.
Box 2: db_accessadmin
Members of the db_accessadmin fixed database role can add or remove access to the database for Windows logins,
Windows groups, and SQL Server logins.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-manage-logins
QUESTION 2
You plan to deploy an Azure SQL Database instance to support an application. You plan to use the DTU-based
purchasing model.
Backups of the database must be available for 30 days and point-in-time restoration must be possible.
You need to recommend a backup and recovery policy.
What are two possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Use the Premium tier and the default backup retention policy.
B. Use the Basic tier and the default backup retention policy.
C. Use the Standard tier and the default backup retention policy.
D. Use the Standard tier and configure a long-term backup retention policy.
E. Use the Premium tier and configure a long-term backup retention policy.
Correct Answer: DE
The default retention period for a database created using the DTU-based purchasing model depends on the service
tier:
Basic service tier is 1 week.
Standard service tier is 5 weeks.
Premium service tier is 5 weeks.
Incorrect Answers:
B: Basic tier only allows restore points within 7 days.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-long-term-retention
QUESTION 3
You need to optimize storage for CONT_SQL3. What should you recommend?
A. AlwaysOn
B. Transactional processing
C. General
D. Data warehousing
Correct Answer: B
CONT_SQL3 with the SQL Server role, 100 GB database size, Hyper-VM to be migrated to Azure VM. The storage
should be configured to optimized storage for database OLTP workloads.
Azure SQL Database provides three basic in-memory based capabilities (built into the underlying database engine) that
can contribute in a meaningful way to performance improvements:
In-Memory Online Transactional Processing (OLTP) Clustered columnstore indexes intended primarily for Online
Analytical Processing (OLAP) workloads Nonclustered columnstore indexes geared towards Hybrid
Transactional/Analytical Processing (HTAP) workloads
References: https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sqldatabase.html
QUESTION 4
A company has many applications. Each application is supported by separate on-premises databases.
You must migrate the databases to Azure SQL Database. You have the following requirements:
Organize databases into groups based on database usage.
Define the maximum resource limit available for each group of databases.
You need to recommend technologies to scale the databases to support expected increases in demand.
What should you recommend?
A. Read scale-out
B. Managed instances
C. Elastic pools
D. Database sharding
Correct Answer: C
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have
varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure SQL Database
server
and share a set number of resources at a set price.
You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based
purchasing model.
Incorrect Answers:
D: Database sharding is a type of horizontal partitioning that splits large databases into smaller components, which are
faster and easier to manage.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool
QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table.
Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID.
Proposed Solution: Separate data into shards by using horizontal partitioning.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
Horizontal Partitioning – Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier. With
this approach, the schema is identical on all participating databases. This approach is also called “sharding”. Sharding
can be performed and managed using (1) the elastic database tools libraries or (2) self-sharding. An elastic query is
used to query or compile reports across many shards.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
QUESTION 6
You need to optimize storage for CONT_SQL3. What should you recommend?
A. AlwaysOn
B. Transactional processing
C. General
D. Data warehousing
Correct Answer: B
CONT_SQL3 with the SQL Server role, 100 GB database size, Hyper-VM to be migrated to Azure VM.
The storage should be configured to optimized storage for database OLTP workloads.
Azure SQL Database provides three basic in-memory based capabilities (built into the underlying database engine) that
can contribute in a meaningful way to performance improvements:
In-Memory Online Transactional Processing (OLTP)
Clustered columnstore indexes intended primarily for Online Analytical Processing (OLAP) workloads
Nonclustered columnstore indexes geared towards Hybrid Transactional/Analytical Processing (HTAP) workloads
References:
https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sqldatabase.html
QUESTION 7
You have a Windows-based solution that analyzes scientific data. You are designing a cloud-based solution that performs real-time analysis of the data.
You need to design the logical flow for the solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Send data from the application to an Azure Stream Analytics job.
B. Use an Azure Stream Analytics job on an edge device. Ingress data from an Azure Data Factory instance and build
queries that output to Power BI.
C. Use an Azure Stream Analytics job in the cloud. Ingress data from the Azure Event Hub instance and build queries
that output to Power BI.
D. Use an Azure Stream Analytics job in the cloud. Ingress data from an Azure Event Hub instance and build queries
that output to Azure Data Lake Storage.
E. Send data from the application to Azure Data Lake Storage.
F. Send data from the application to an Azure Event Hub instance.
Correct Answer: CF
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources: Azure
Event Hubs Azure IoT Hub Azure Blob storage
References: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
QUESTION 8
You are designing a recovery strategy for your Azure SQL Databases.
The recovery strategy must use default automated backup settings. The solution must include a Point-in time restore
recovery strategy.
You need to recommend which backups to use and the order in which to restore backups.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
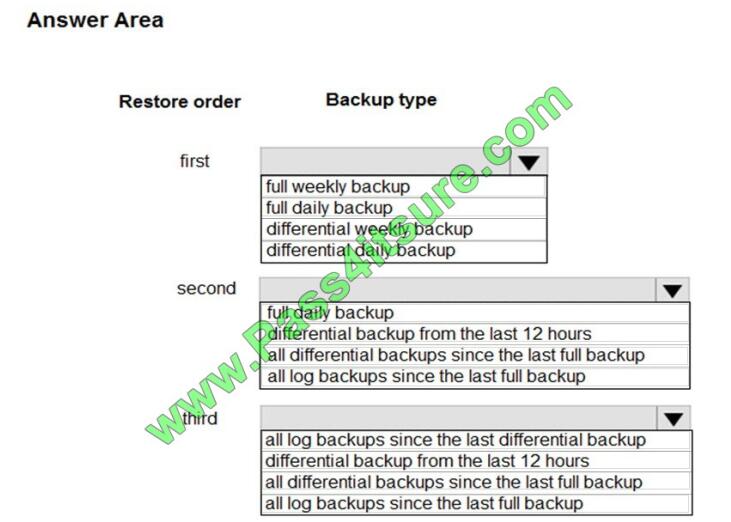
Correct Answer:

All Basic, Standard, and Premium databases are protected by automatic backups. Full backups are taken every week,
differential backups every day, and log backups every 5 minutes.
QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table.
Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID.
Proposed Solution: Separate data into customer regions by using horizontal partitioning.Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
We should use Horizontal Partitioning through Sharding, not divide through regions.
Note: Horizontal Partitioning – Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier.
With this approach, the schema is identical on all participating databases. This approach is also called “sharding”.
Sharding can be performed and managed using (1) the elastic database tools libraries or (2) self-sharding. An elastic
query is used to query or compile reports across many shards.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
QUESTION 10
You need to design the storage for the telemetry capture system. What storage solution should you use in the design?
A. Azure Databricks
B. Azure SQL Data Warehouse
C. Azure Cosmos DB
Correct Answer: C
QUESTION 11
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be
used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information.
The summary information page must meet the following requirements:
Display a summary of sales to date grouped by product categories, price range, and review scope.
Display sales summary information including total sales, sales as compared to one day ago and sales as compared to
one year ago.
Reflect information for new orders as quickly as possible.
You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.
Hot Area:

Correct Answer:
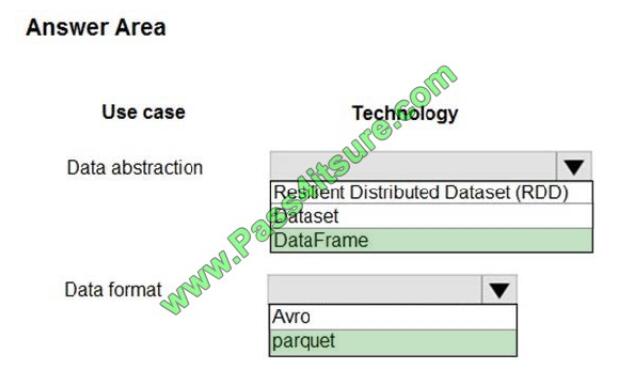
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst.
Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming.
Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores
data in columnar format, and is highly optimized in Spark.
Incorrect Answers:
DataSets
Good in complex ETL pipelines where the performance impact is acceptable.
Not good in aggregations where the performance impact can be considerable.
RDDs
You do not need to use RDDs, unless you need to build a new custom RDD.
No query optimization through Catalyst.
No whole-stage code generation.
High GC overhead.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-perf
QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will
use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be
removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes
that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if
corruption is detected.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption
checks complete.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
QUESTION 13
A company installs IoT devices to monitor its fleet of delivery vehicles. Data from devices is collected from Azure Event
Hub.
The data must be transmitted to Power BI for real-time data visualizations.
You need to recommend a solution.
What should you recommend?
A. Azure HDInsight with Spark Streaming
B. Apache Spark in Azure Databricks
C. Azure Stream Analytics
D. Azure HDInsight with Storm
Correct Answer: C
Step 1: Get your IoT hub ready for data access by adding a consumer group.
Step 2: Create, configure, and run a Stream Analytics job for data transfer from your IoT hub to your Power BI account.
Step 3: Create and publish a Power BI report to visualize the data.
References:
https://docs.microsoft.com/en-us/azure/iot-hub/iot-hub-live-data-visualization-in-power-bi
Full Microsoft DP-201 dumps https://www.pass4itsure.com/dp-201.html
Microsoft DP-201 Pdf Dumps
[PDF Download] https://drive.google.com/open?id=1NvvwCISycyoz3S5RYg2Rpjm_QdeFlF7w
Latest Microsoft other Certification AI-100 exam dumps, AI-100 Exam Practice Tests | 100% Free
Pass4itsure discount code 2020

Studying DP–200, DP–201 study guide to help you 100% pass exam. https://www.pass4itsure.com/role-based.html Download DP–200 pdf and DP–201 pdf.